The Future of Genome Sequencing: Breakthroughs Shaping Tomorrow
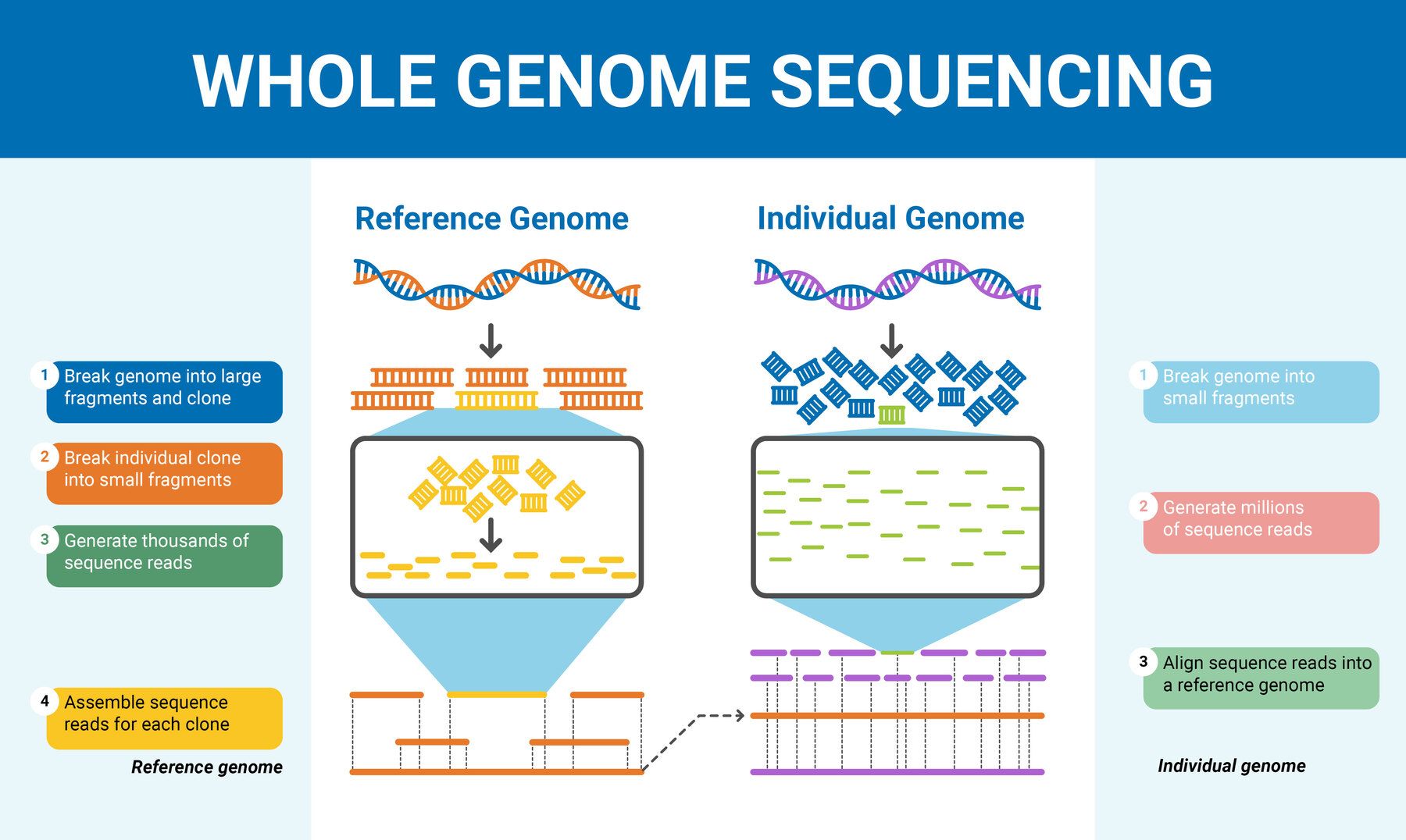
When I first dove into genome sequencing during my postdoc, it felt like trying to catch a sprinting train—constantly trying to keep up with breakthroughs that seemed to come overnight. Just a few years ago, sequencing a genome was a massive, expensive ordeal, locked away in specialized labs with machines the size of refrigerators. Now? You can literally fit a sequencer in your pocket and analyze data overnight on a laptop. It’s both thrilling and overwhelming. For a more detailed foundation, you might want to check out this comprehensive guide to genome sequencing.

But here’s the truth: beneath all the buzz and jargon, the core breakthroughs come down to four big things—speed, accuracy, cost, and accessibility. These factors are what’s driving genome sequencing out of ivory towers and into everyday use. Let me share what really matters, based on hands-on experience (and some hard-earned mistakes) that no paper could teach me.
Nanopore Sequencing: How the MinION Changed My Lab Workflow (And What No One Warned Me About)
Oxford Nanopore’s MinION is often called a “miracle device” — and honestly, it’s close. It’s roughly the size of a USB stick but can sequence whole DNA or RNA strands in real time, wherever you happen to be. I still remember our first field test during a bacterial outbreak: instead of waiting three days for results from our giant Illumina sequencer back at the university core facility, we had preliminary data in under four hours. That speed completely flipped how we approached diagnostics.
Sounds perfect, right? Not quite. The early nanopore reads felt like trying to read your favorite book with half the words smudged out. Error rates were two or three times higher than traditional short-read platforms. For weeks, we tried forcing these messy reads through standard analysis pipelines that just weren’t designed for nanopore quirks—wasting time and patience.
What turned things around was switching to newer base-calling software like Guppy, paired with error-correction tools such as Medaka and marginPolish. Suddenly, those fuzzy reads cleaned up dramatically.
So here’s my advice: don’t expect plug-and-play perfection when adopting emerging tech. Plan for trial and error—test different software versions, tweak parameters constantly, and if possible, combine nanopore data with short-read sequences for best results. It’s messy at first but worth it. For a deeper dive into the variety of sequencing platforms available, see the different types of genome sequencing technologies.
CRISPR Isn’t Just for Editing: Using It to Zoom In on Cancer Mutations
Everyone knows CRISPR as the gene editor du jour—but its role in sequencing is equally exciting and often overlooked. In one project with a tiny oncology group (just four of us), we combined CRISPR-based enrichment with nanopore sequencing to hunt down sneaky cancer mutations lurking in complex genomic regions.
Instead of blindly sequencing everything—which wastes precious time and money—we used CRISPR guides to pull out only the DNA fragments that mattered before loading them into the sequencer. This targeted approach slashed sequencing costs by nearly 60% while boosting mutation detection sensitivity.
Was it smooth sailing? Far from it! Our first set of CRISPR guides missed key variants because we underestimated off-target effects—a rookie mistake that cost us weeks of redesigns and controls testing.
The big takeaway here: targeted sequencing with CRISPR isn’t just theory—it’s practical and cost-effective—but only if you invest upfront time designing your guides carefully and validating your approach thoroughly.
SMRT Sequencing: When High Accuracy Is Absolutely Non-Negotiable
Pacific Biosciences’ Single-Molecule Real-Time (SMRT) sequencing still holds court when you need high accuracy and long reads. In one project mapping structural variants within repetitive DNA regions—where nanopore struggled—we turned to PacBio’s Sequel II system.
What blew me away wasn’t just its precision but also the kinetic data it provides about DNA modifications like methylation—all without extra sample prep steps! That additional epigenetic insight gave us clues about gene regulation that would’ve been totally invisible otherwise.
Downside? These machines are bulky monsters costing hundreds of thousands—not something you’d lug into the field anytime soon. But for research where every base counts? Indispensable. For more on how these technologies fit into the bigger picture, see this complete overview of genome sequencing.

AI Isn’t Magic — It’s Smart Data Handling With Caveats
Terabytes of raw sequence data pour in daily—and numbers alone don’t mean much without interpretation. AI-powered tools have revolutionized this step but don’t be fooled into thinking they’re flawless black boxes.
I spent months running DeepVariant on tumor samples before learning a painful lesson: blindly trusting AI-generated variant calls led me down rabbit holes chasing false positives that could have derailed clinical decisions.
The trick? Combine AI-driven variant calling with expert manual review—use DeepVariant or similar tools for speed but always follow up by inspecting calls visually (with tools like IGV) and confirming suspicious results using orthogonal methods.
If you’re new here: start by running DeepVariant or Nanopolish yourself on public datasets such as NA12878 (a widely studied human genome sample). Getting hands-on will demystify how these tools work — their strengths and their blind spots — saving you headaches later on.
Big Picture Innovations on My Radar (And Why You Should Care)
-
Sequencing Costs Dropping Toward $100: Thanks to innovations in microfluidics miniaturization and chemistry tweaks, whole-genome sequencing might soon be as affordable as common blood tests—at least in well-funded health systems. Personalized medicine moving beyond elite centers is just around the corner. For more on this, see cost trends and accessibility of genome sequencing over time.
-
Real-Time Clinical Decisions Anywhere: Portable sequencers plus AI could enable rural clinics to diagnose infections or cancers onsite within hours instead of weeks—a genuine game-changer for patient outcomes where access is limited.
-
Multi-Omics Integration Expanding: DNA alone no longer tells the full story. Platforms that read RNA directly (like nanopore) or simultaneously detect epigenetic marks open doors to understanding diseases through multiple biological layers at once—a huge leap forward.
What I Wish Someone Had Told Me Early On
Don’t bet everything on one shiny new technology too soon—I’ve seen teams put all their eggs in nanopore baskets only to scramble when accuracy problems delayed projects by months.
Mix technologies strategically instead—use nanopore for quick insights but rely on traditional short-read or SMRT platforms when precision matters most.
Also: quality control isn’t optional; skipping rigorous filtering early on led me down wild goose chases chasing phantom mutations caused by noise rather than biology.
How You Can Start Right Now Without Getting Overwhelmed
-
Order an Oxford Nanopore MinION Starter Pack: It costs under $1,000 and includes everything needed for your first runs at home or bench—hands-on learning beats theory every time. Check Oxford Nanopore’s website for starter kits plus tutorials tailored for beginners.
-
Try Open-Source AI Tools Yourself: Download DeepVariant or Nanopolish from GitHub and run them on publicly available datasets like NA12878 (1000 Genomes Project)—seeing how these tools analyze real data will demystify AI-powered variant calling far faster than reading papers alone.
-
Subscribe Selectively: Instead of drowning in every paper or press release out there, follow two trusted newsletters such as Nature Biotechnology and Genome Biology. Set aside 15 minutes weekly to skim headlines relevant to your niche—it keeps you informed without burnout.
-
Build Cross-Disciplinary Connections: Genome science isn’t just wet lab or dry lab anymore—it requires both plus clinical insight mixed together. Join online forums like BioStars or SeqAnswers—or local meetups where computational biologists, clinicians, and bench scientists hash out real-world challenges openly.
Quick Recap — Key Takeaways
- Emerging technologies excel differently: use nanopore for speed/accessibility; SMRT for high accuracy; CRISPR-based enrichment to focus efforts.
- Expect bumps early on—embrace iterative testing rather than expecting instant perfection.
- Combine AI tools with manual review; don’t trust “magic” black boxes blindly.
- Invest time upfront designing guides or QC processes—it pays off.
- Start small with accessible kits & open-source software; learn by doing.
- Stay connected across disciplines—it makes problem-solving way easier.
If I could jump back in time to tell my younger self one thing: expect failures—they’re part of learning—but pair innovation with patience and quality checks every step of the way. That balance turned fumbling early nanopore runs into reliable workflows now trusted across projects large and small.
So why wait? Your genomic future is already here waiting patiently for you to unpack it piece by piece—with curiosity, persistence, and a dash of humor when things go sideways (because trust me—they will).
Ready to dive in? The adventure starts now!



